So, you have a job failing, possibly a multi-step job and you’ve either ran into the “Cannot process loc” error or something like “Bad File Status 4 7 On File <Filename>”
This isn’t allowing the job to run and or pick lists to be printed.
First make sure you verify with your IT team that this job is not going to run soon again and that none of the other programs are running.
Now to resolve this issue, you will need to use a quick paint screen to change the OE-RUN-STS field in the ICLOCATION file from 2 to 0.
6 – Ic Reorder Running (IC140, IC141, IC142) The IT Team can use command such as tmmon to verify.
If the job is scheduled to run again automatically, allow it to do so and it should complete and the pick lists should be printed. Make sure other jobs are not scheduled to run around the same time you’re changing the OE-RUN-STATUS.
Lastly, if you’re running frequently for the same parameters, change the pgmdef, Execute parameter to Non-Concurrently to ensure the job prior has completed before the next one attempts to run.
The Lawson Form Transaction node is used to create AGS calls to make updates to Lawson Forms. If you already have an AGS call built, you can simply put it in the property window of the node. You can also build an AGS call from scratch by clicking the “Build” button and going through the Wizard. The connection should already be using your Infor Lawson configuration set, but you can set that explicitly if desired. For this node to work, it is important that you have the Infor Lawson tab configured in your “main” configuration set in Landmark/IPA. You can get more information on how to do that here.
In the Build wizard, select your product line, the module, and the token where you are making updates. The Method(s) available to that token will be all the methods available to the token in Lawson portal.
Move over the field(s) that you want to update. Make sure you include the fields that are required on the form. If you are making a change, make sure you include the key fields and their values for the item you are changing. The Value can be a hard-coded value, or a variable available to the node.
Click finish when you have filled in all your desired fields. The AGS call will now appear in the property window.
https://www.nogalis.com/wp-content/uploads/2020/07/IP-Designer-Series-Lawson-Form-Transaction.jpg470470Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2020-07-07 08:08:562021-02-10 11:51:28IP Designer Series – Lawson Form Transaction
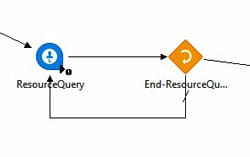
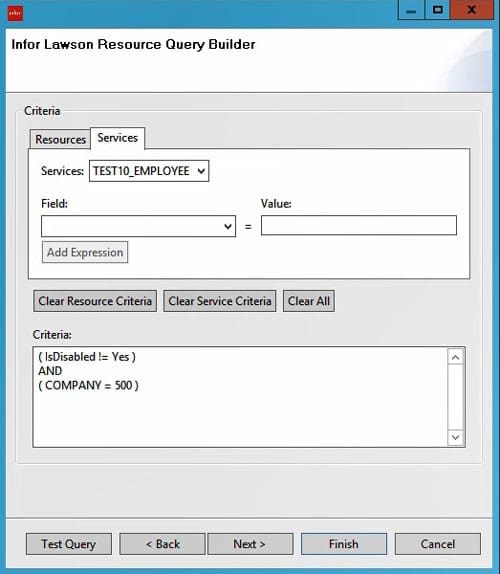
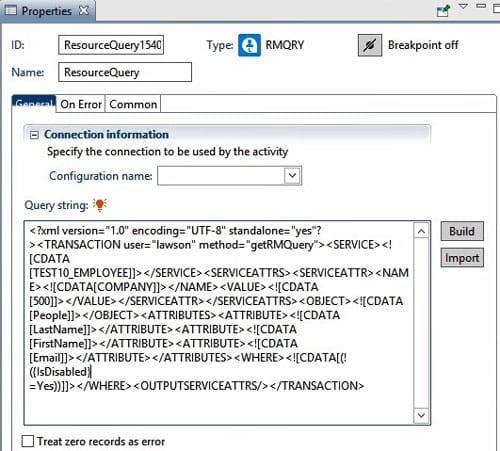
The Resource Query node can be used to query Lawson user (RM) data in Lawson Security. This node can be especially useful for automated user functions, such as onboarding and offboarding.
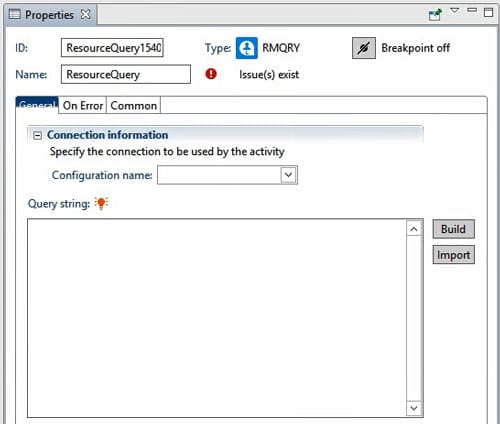
To start a query, click “Build” on the properties screen.
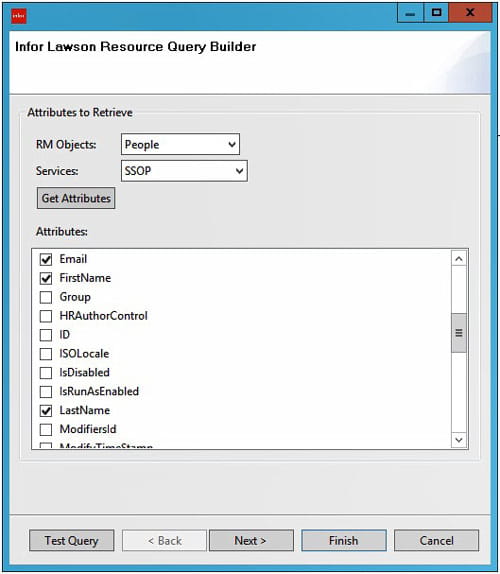
Select the RM Object and the Service that you want to use and click “Get Attributes”. Choose the Attributes that you want to retrieve from each user’s record. Then click “Next” to select the search criteria.
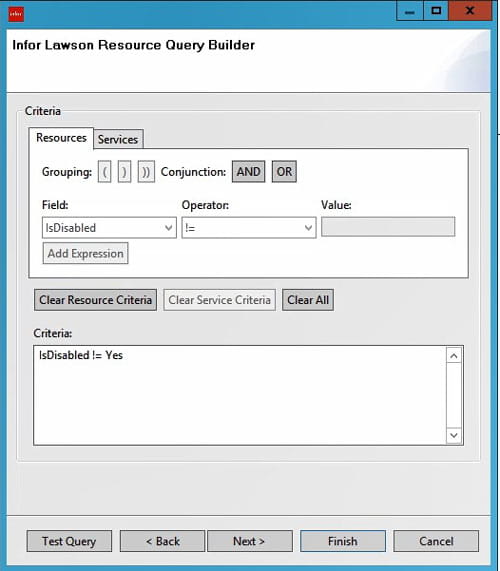
You can choose users based on their Resource (RM) data or Services, or both.
Once you click finish, the query should be built in the properties window.
https://www.nogalis.com/wp-content/uploads/2020/06/IP-Designer-Series-Resource-Query.jpg470470Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2020-07-01 08:04:002021-02-10 11:52:31IP Designer Series – Resource Query
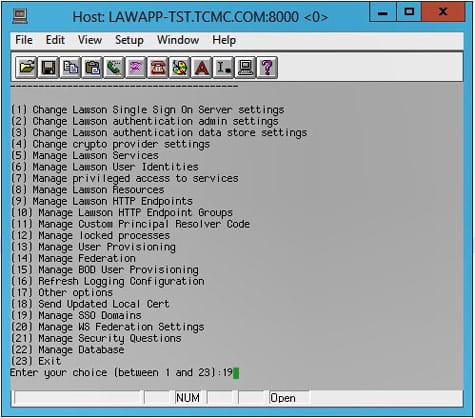
There are a couple of authentication options when it comes to your external Lawson website. If you want to authenticate using AD FS, you will have to put an AD FS server on the DMZ and make it externally facing. If that is not an option at your organization, another option is to authenticate using the LDAP Bind. Even when you implement AD FS for Lawson authentication, some pieces of the application (such as Add-ins) still require LDAP Bind. So, you can set up your external website to take advantage of that service instead of AD FS.
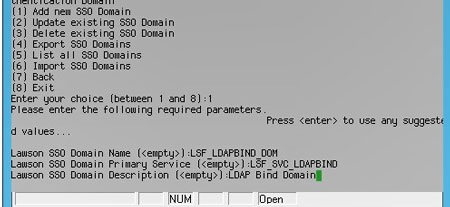
The first step is to create an SSO domain if you don’t already have one.
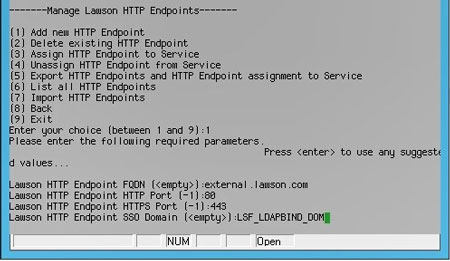
Next, you will need to create a new HTTP endpoint with the values:
FQDN – the fully-qualified domain name of your externally facing web server
HTTP Port – the HTTP port your Lawson site uses (can be -1 if you want to disable HTTP)
HTTPS Port – the HTTPS port your Lawson site uses
SSO Domain – the LDAP Bind domain from the step above
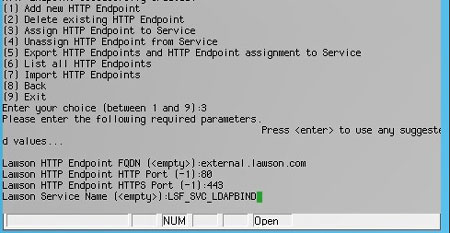
Next, assign your new endpoint to your LDAP Bind service. If you are still using LS as STS (as opposed to AD FS) for authentication to Lawson, this service is probably “SSOP”. Otherwise, it is the service that was set up for LDAP Bind in applications like MS Add-ins or Lawson Security Administrator.
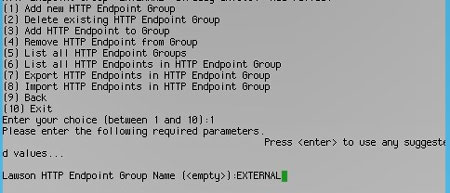
Next, you need to create an endpoint Group. Give it a meaningful name that will let you know this is the group for external Lawson.
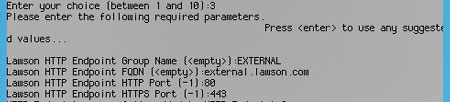
Now, assign your new endpoint to the endpoint group you just created.
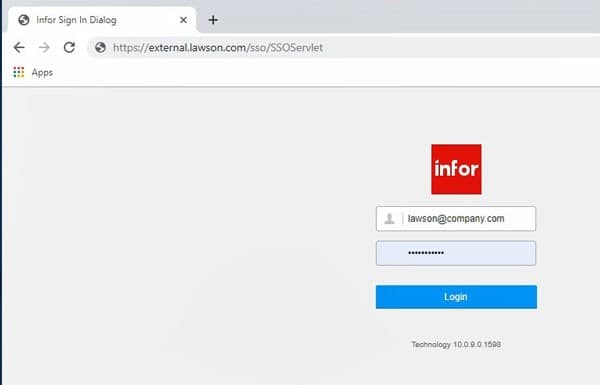
Recycle services (or reboot your server), and do your smoke test. Check the SSOServlet URL to make sure you are presented with the Infor Lawson login screen:
https://www.nogalis.com/wp-content/uploads/2020/06/Configure-External-Lawson-to-Authenticate-Against-LDAP-Bind.jpg470470Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2020-06-29 07:23:302021-02-10 11:54:29Configure External Lawson to Authenticate Against LDAP Bind
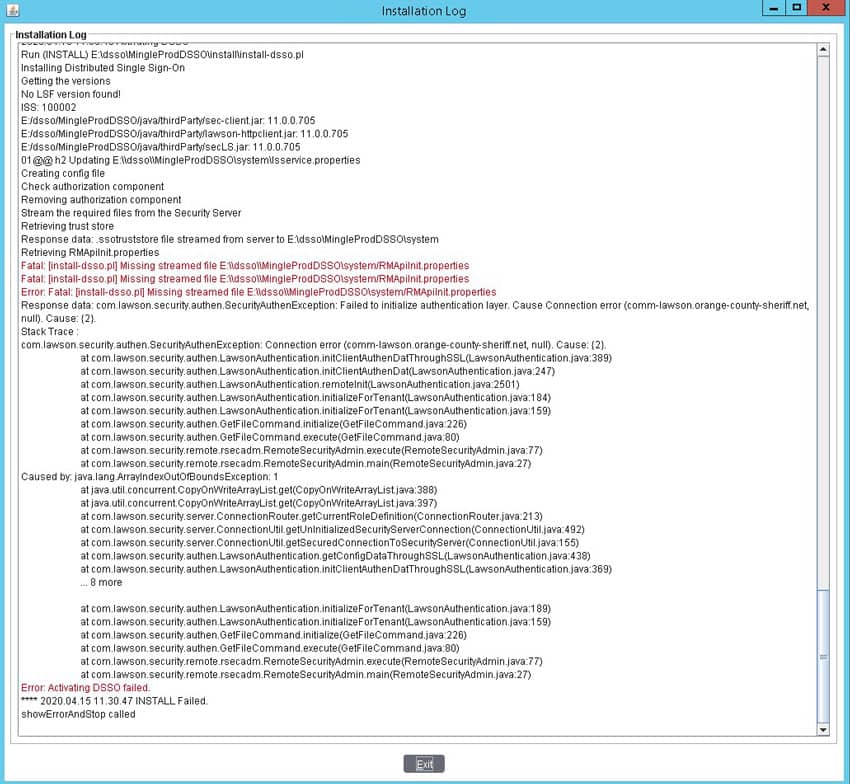
There is a common issue that may present itself when installing Distributed Security Package (DSP) for Ming.le. The install will fail when trying to retrieve the trust store from the LSF server, with a message similar to the screenshot below. There will also be exceptions in the LASE logs on the LSF server indicating a certificate issue (“Received fatal alert: certificate_unknown”).
Except from LASE log:
20-04-15 19:58:11:874 12 default.SEVERE authen.SSOServer.run(): SSOServer: Got unexpected exception when processing new secured connection com.lawson.security.server.LawsonNetException: Got exception while writing to connection /172.18.8.58,40001 Stack Trace : com.lawson.security.server.LawsonNetException: Got exception while writing to connection /172.18.8.58,40001 at com.lawson.security.server.AbstractDefaultEventSource.write(AbstractDefaultEventSource.java:299) at com.lawson.security.server.Connection.<init>(Connection.java:170) at com.lawson.lawsec.authen.SecuredConnection.<init>(SecuredConnection.java:39) at com.lawson.lawsec.authen.SSOServer.run(SSOServer.java:180)Caused by: javax.net.ssl.SSLHandshakeException: Received fatal alert: certificate_unknown at sun.security.ssl.Alerts.getSSLException(Alerts.java:192) at sun.security.ssl.Alerts.getSSLException(Alerts.java:154) at sun.security.ssl.SSLSocketImpl.recvAlert(SSLSocketImpl.java:2020) at sun.security.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:1127) at sun.security.ssl.SSLSocketImpl.performInitialHandshake(SSLSocketImpl.java:1367) at sun.security.ssl.SSLSocketImpl.writeRecord(SSLSocketImpl.java:750) at sun.security.ssl.AppOutputStream.write(AppOutputStream.java:123) at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82) at java.io.BufferedOutputStream.flush(BufferedOutputStream.java:140) at java.io.DataOutputStream.flush(DataOutputStream.java:123) at com.lawson.security.server.AbstractDefaultEventSource.writeMsg(AbstractDefaultEventSource.java:348) at com.lawson.security.server.AbstractDefaultEventSource.write(AbstractDefaultEventSource.java:287) … 3 more
If you come across this issue, you will need to add a line to the lsservice.properties file.
To handle multiple certificate in the keystore when LS as STS (Verify if your SSOP service definition has any of these listed for the PRIMARYTARGETLOOKUP; Use Ldap Binds, Verify passwords in Lawson Security, Use Claim Based, or Kerberos) or “AD FS” is configured, edit LAWDIR/system/lsservice.properties and add the property below.
server.keystore.use.classic=false
In a Federated environment the property needs to be added in federated systems that are configured to use STS or ADFS such as in the Landmark System configuration in the LAENV/system/lsservice.properties file there
Once this line has been added it will not take effect until you stop WebSphere and the LSF environment and then start the LSF environment and start WebSphere.
**NOTE**
If your LSF environment is federated with Landmark you should stop and start landmark after the LSF side of things are back up and running.
https://www.nogalis.com/wp-content/uploads/2020/06/DSP-for-Ming.le-Fails-on-Installation.jpg470470Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2020-06-25 08:12:252021-02-10 11:55:07DSP for Ming.le Fails on Installation
If you did an upgrade-in-place of LBI and are experiencing issues with it, you can revert to the previous version.
Before you begin a task like this, always get snapshots of your sever!!!
****If you don’t have a backup of your pre-upgrade database, then you won’t be able to complete these steps. You can’t revert the database changes. Always start with a database backup!!!****
Revert CRAS
You don’t need to perform this step unless your previous version of LBI requires a different version of CRAS. To revert Crystal Report Application Server, you need to uninstall the new version, and reinstall the old version. CRAS does not uninstall cleanly, so once you step through the wizard, and reboot the server, you will need to clear out the components left behind in the registry. Here are the registry keys you may need to delete (key names may differ based on your version):
HKEY_LOCAL_MACHINE\SOFTWARE\SAP Business Objects\Suite XI 4.0\Crystal Reports\
HKEY_CURRENT_USER\Software\ SAP Business Objects\Suite XI 4.0\Crystal Reports
HKEY_USERS\S-#-#-##-…-####\Software\ SAP Business Objects\Suite XI 4.0\Crystal Reports
Reboot again. Try reinstalling the older version. If you get any errors during the reinstall, you may have left behind some keys in the registry. You can search the registry for “Crystal”.
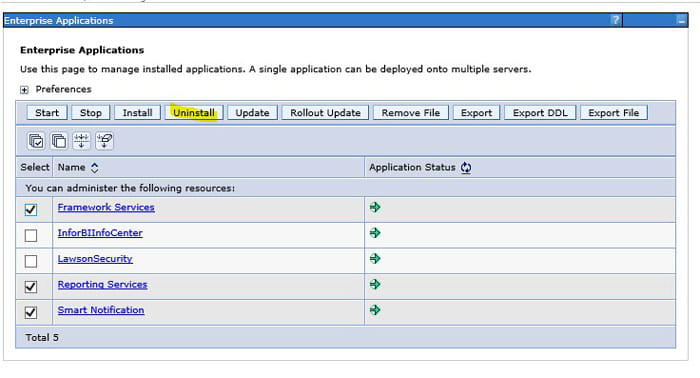
Uninstall LBI From WebSphere
In WebSphere Administration Console, navigate to Applications > Application Types > WebSphere enterprise applications. Select all of your LBI applications (Framework Services, Reporting Services, Smart Notification), and Uninstall.
Reboot the server.
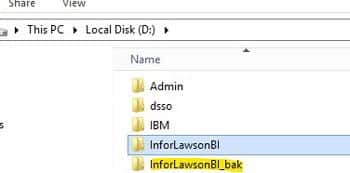
Rename the LBI Install Directory
Stop the IBM WebSphere Application server service, then rename your LBI install directory. This way, you can install your previous version of LBI in the same directory.
Restore Data
Restore your pre-upgrade data to the RS, FS, and SN databases.
Reinstall LBI
Run the LBI install wizard for your previous version. Verify that the applications were deployed to WebSphere and that they were started. Perform smoke tests.
You should be ready to retry the upgrade! LBI upgrades can be finicky with WebSphere and database updates. I recommend rebooting between each component update. So, reboot before you begin. Then reboot after upgrading Framework Services. Then reboot after upgrading Reporting Services. And so on…
https://www.nogalis.com/wp-content/uploads/2020/06/Revert-LBI-to-a-Previous-Version.jpg470470Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2020-06-22 08:13:212021-02-10 11:58:05Revert LBI to a Previous Version
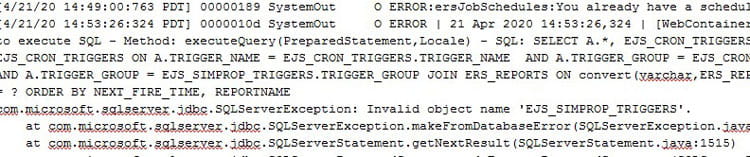
When using the wizard to perform an in-place update to LBI, occasionally the database scripts will fail without notification. The issue will typically present itself when you restart the IBM services and the SystemOut.log throws database errors, such as “invalid object name” or “field does not exist” after the application attempts to run a query.
The good news is that the database update scripts can be run manually. These scripts can be found at <lbi_install_dir>\<product>\<product>.ear\<product>war-<version>.war\WEB-INF\rdbms\<database type>
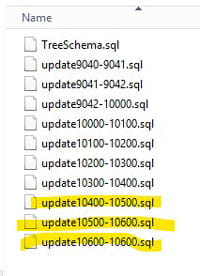
You want to run all the update scripts that exist between your old version and your new version. So, if you are upgrading from 10.4 to 10.6, you would run the highlighted scripts:
***IMPORTANT: DO NOT run the oracle.sql or TreeSchma.sql script. They will drop all your tables.
https://www.nogalis.com/wp-content/uploads/2020/06/Database-Errors-after-an-LBI-Upgrade.jpg470470Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2020-06-16 07:23:092021-02-10 11:59:18Database Errors after an LBI Upgrade
There is no doubt that the right managed service partner (MSP) can elevate your business and bring all sorts of new possibility within reach. Here are some ways that the right MSP relationship can benefit your organization.
Economy of scale – Your managed service provider is likely servicing dozens of customers whose business is similar to yours. Therefore, instead of one subject matter expert (SME) to work with each client, a SME can handle the requests of three or four customers and reduce the overall costs.
24/7/365 coverage – Having constant, around-the-clock coverage of your entire application infrastructure is not realistic for every business. However, managed service companies specialize in this specific mode of operation and depending on the engagement will provide this coverage at no additional cost.
Cross-client experience sharing – Your managed service provider likely has several customers who work with the same set of applications as your organization and therefore go through the same changes at roughly the same times. Very often when you report an issue to your managed service provider, they have been working with other clients on the same problem and can resolve it very quickly. This cross-client experience sharing is what gives MSPs the leverage to offer you lower costs than you would get on your own.
Training – To maintain all your existing applications and to keep up with ongoing changes, you have to keep your staff trained and certified in multiple skill sets. It’s an unending task that is never near completion. Most IT managers will admit that their staff is far behind on their training plan. Your MSP however is trained and certified in all the right areas and maintains their certifications with all the software partners. You no longer have to worry about keeping up on a skill set that doesn’t have to do with your core business.
Business focus – Your primary business is more than likely not managing applications. In an ideal world all your company staff would be focused on the core of your business and not on operating payroll, financial, and inventory control applications. That is exactly the kind of focus you will gain by partnering with the right MSP.
Proactive maintenance – Most IT departments are focused on keeping the lights on and break-fix issues. Proactive maintenance has become a luxury most companies can’t afford and rarely even think about. Your managed service partner profits only when the number of hours it takes to maintain your account is less than the monthly fee you have committed to. With interests aligned in this way, your MSP will take a more active role in making sure things are maintained well and they break far less often.
Skills coverage – Many of the skills required throughout the year to maintain all your applications are one-off skills that never really become relevant again. It doesn’t make a lot of sense to train your staff in installation, upgrade, and setup of your applications when those tasks are only happening once every few years and changing each time. Your MSP partner, however, uses those skills with several clients and will always have trained staff on hand for such tasks.
Single point of ownership – Having single point of ownership for trouble tickets, maintenance, change control, SLAs, and application related upkeep ensures that work gets done without the need to coordinate between several parties and the buck doesn’t get passed around.
Reduced downtime – Proactive maintenance, the presence of a skilled and ever-ready work force, and around-the-clock coverage means the potential for downtime would be reduced to nearly zero.
Leaner staff – With all the distracting applications managed by your MSP, you are now free to focus on the core applications that run your business and give you competitive advantage in the marketplace. Your team can be leaner and more focused without the need for staff with narrow skills for single-use applications. Most organizations are able to reduce their teams by 30% when partnering with a MSP.
https://www.nogalis.com/wp-content/uploads/2020/06/10-Benefits-of-Hiring-a-Managed-Service-Partner.jpg470470Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2020-06-11 08:16:582021-02-10 12:00:2710 Benefits of Hiring a Managed Service Partner
In today’s fast changing IT landscape, you need a managed service provider (MSP) that understands your needs and whose business model is aligned with your organization. Keep in mind the following areas when choosing a managed service provider for your business.
Specific application expertise: There are thousands of managed service providers within the US. Many of them claim to work with dozens of applications. It is important however that your main applications are properly supported, and the expertise of your MSP team exceeds and enhances that of your own internal team. For that reason, we focus mainly on Infor, Lawson and Kronos applications and some of the ancillary applications that are usually installed with them (MHC, BSI, API, ImageNow, Ascend …). Make sure that your MSP partner is in good standing with your software vendor and is certified to deliver services related to those applications.
Industry specific knowledge: Every industry has its own special challenges and choosing a managed service partner who has worked with clients in your industry can make a big difference in your level of success. An experienced MSP can also bring best practices from others in your vertical to help you be more efficient.
Client references: The best indicator of the quality of an MSP is what their clients have to say about them. Check reviews and ask to speak to their customers before you select an MSP.
State-side availability: Many of our clients find it imperative that our staff is not outsourced to foreign countries and all the work is performed state-side. If this is important to your organization, ensure that your MSP partner has a presence where you do your business and will not be impacted by geo-political issues that might otherwise interrupt their services.
Methods of engagement: You need to find out ahead of time how your users can engage with your MSP. Some MSPs employ a cumbersome ticketing process that can add hours if not days to the resolution of each issue. We have long adopted a policy of working within whatever ticketing system our clients are already working with so as to remove any friction from resolving issues. We also encourage customers to call or emails us directly if they feel like that will facilitate faster resolution. Be sure to understand the way your MSP works before committing to long term relationships.
Avoid long term commitments: Committing to a service provider is a big business decision that can impact your organization significantly. It is always advised to insist on a short-term commitment whenever possible. We don’t lock our clients into long term contracts for this very reason. In reality, if a customer wants to change service providers, it doesn’t make sense to force them to stay, but many MSPs still insist on multi-year contracts in order to break even with long and expensive sales cycles and hefty commissions.
https://www.nogalis.com/wp-content/uploads/2020/06/How-to-choose-a-managed-service-partner.jpg470470Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2020-06-04 09:12:252021-02-10 12:02:02How to choose a Managed Service Partner
Configuring Lawson on an external web server is pretty straightforward…until you have issues. The most common symptom I have run across is a 404 error when you open the web page, which typically indicates that external web server can’t find sso/sso.js. (A quick Fiddler session will confirm that for you). That is the first time the external web server is reaching out to the Lawson application server, so that error message indicates that you have a communication failure between the two web servers. There can be many reasons for that communication failure, from bad plug-in files to bad certificates. Here are just a few things to review:
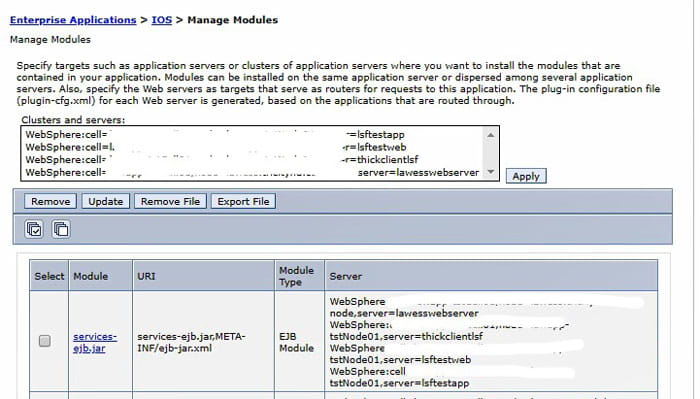
Make sure your modules are mapped
Navigate to WebSphere > Applications > Application Types > Websphere enterprise applications. Select the IOS application and click “Manage Modules”. Make sure all modules are mapped to all servers (web and application). Do this for IOS and LawsonSecurity. You can also check RQC and BPM for good measure.
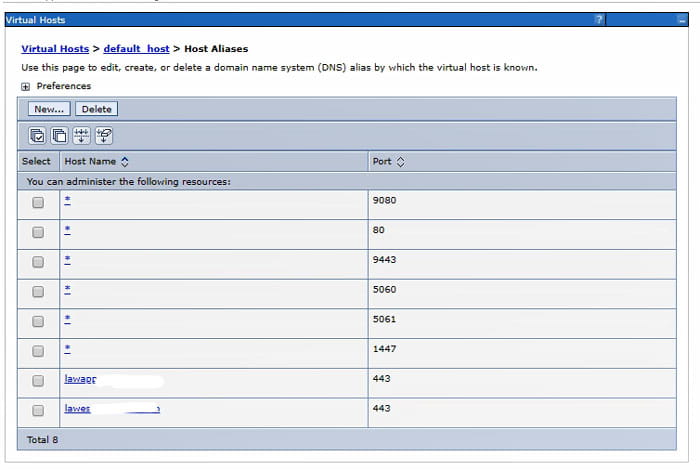
Check Virtual Hosts
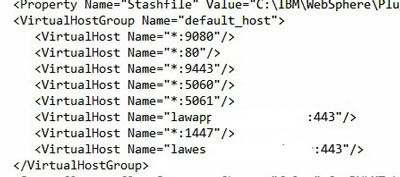
Navigate to WebSphere > Applications > Application Types > Websphere enterprise applications. Select IOS. Under “Web Module Properties” on the right, click “Virtual Hosts”. Make note of which virtual host IOS is using. Then, under Environment > Virtual Hosts, click the host being used by IOS. Make sure that your External Web Server port is in the host alias list. NOTE: if your external web server is using the same port as your internal web server, it is best to give explicit aliases for that port. Add an alias with the fully qualified domain for each server, and the port being used.
Check your plugin-cfg.xml
Make sure the plugin-cfg.xml on your external web server looks right. On your external web server, you should find the plugin-cfg file at <IBM Plugins Directory>/config/<Web Server Name>
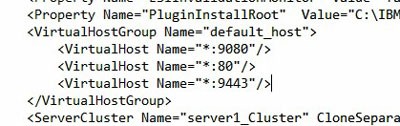
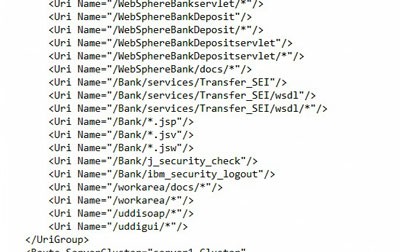
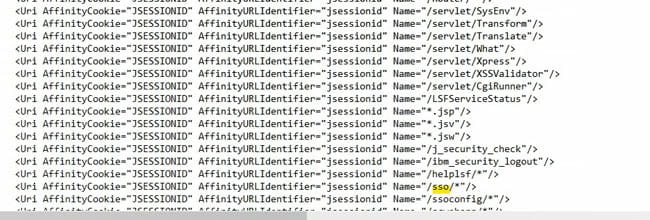
It should have some basic properties. First of all, it should contain all the virtual hosts that you just checked in step 2. Secondly, it should contain some Uri’s specific to Lawson (not just the default WebSphere application). Here is an example of a “bad” plugin-cfg file compared to a “good” one.
BAD – does not have all my virtual hosts
BAD – does not have any lawson-specific Uri’s
GOOD – all my virtual hosts are represented, including the host aliases I set up for duplicate ports
GOOD – there are my lawson-specific Uri’s, including that sso directory that was giving me trouble at the very beginning
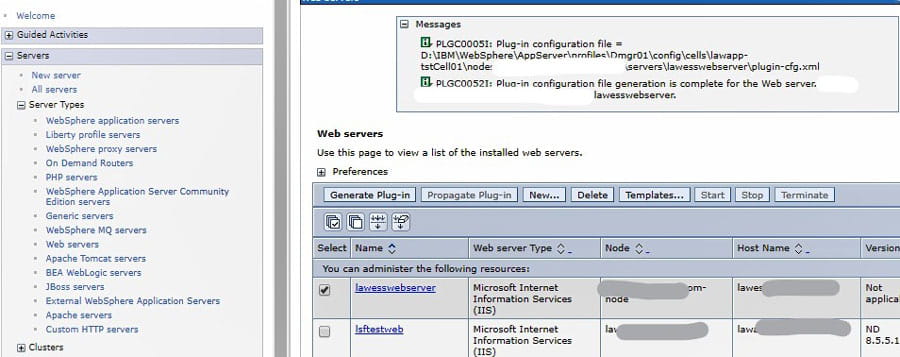
The best way to resolve issues with your plug-in file is to regenerate it from your Application Server WebSphere console. Go to WebSphere > Server Types > Web Servers. Select your external web server and click “Generate Plug-in”. You can’t propagate it, because it is on an external server, and it belongs to an unmanaged node. So, make note of where the config files was saved (at the top in the Messages section). Navigate to that location on your server and grab the file. Copy the plugin-config.xml file and the plugin-key.kdb from that location to the plugins location noted above on your external web server. Restart your World Wide Web Publishing service on the external web server, and test your external URL.
Check the WebSphere certs
If you are having certificate issues in WebSphere, you might be seeing the 404 error in a Fiddler session, but you might also be seeing a 500 error. Your first stop is the http_plugin.log on the external web server. If there are certificate errors, they will be noted here. Look for “GSK” errors. This could mean your WebSphere certificate has expired, or there isn’t a trust between the application certificate and the external web certificate.
In WebSphere, navigate to Security > SSL certificate and key management > Key stores and certificates > CellDefaultKeyStore > Personal Certificates. Make note of the serial number on that certificate. Then go to the CMSKeyStore for your external web server. Again, make note of the serial number. If they are not matching, you’ll need to replace your external key store cert with the internal one.
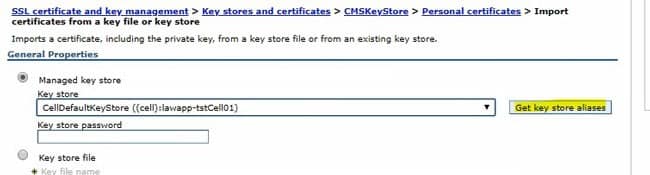
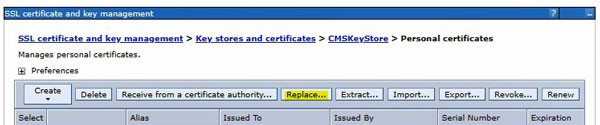
To do that, first import the CellDefaultKeyStore into the web server CMSKeyStore. In the CMSKeyStore > Personal Certificates for your external web server, click the “import” button.
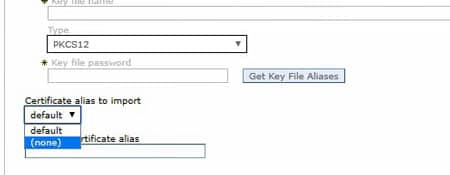
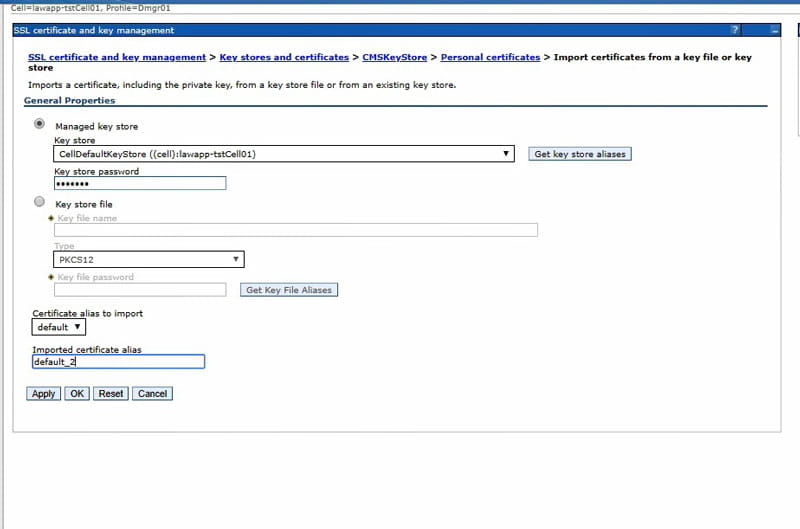
In the dropdown, select the CellDefaultKeyStore, and click “Get key store aliases”. This should populate the “certificate alias to import” down below. Select the correct certificate to import (most likely “default”).
Give the certificate a new alias. Click “Apply” and save changes.
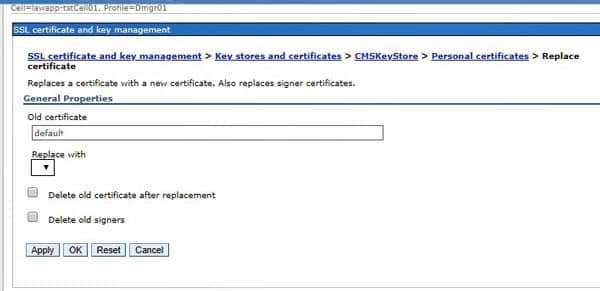
Now, you need to replace the old certificate with the new one. Under certificates, select the “old” cert and click “replace”. Select your new cert in the “replace with” box. You can choose to delete the old cert at this time, but it’s actually safer to delete it manually after you smoke test. Restart the application server, or better yet, reboot!
https://www.nogalis.com/wp-content/uploads/2020/05/Troubleshooting-External-Web-Server-Issues.jpg470470Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2020-06-02 07:51:192020-05-27 18:04:55Troubleshooting External Web Server Issues